- Sample n on-policy completions for a prompt.
- Embed sampled and reference completions with a frozen feature network.
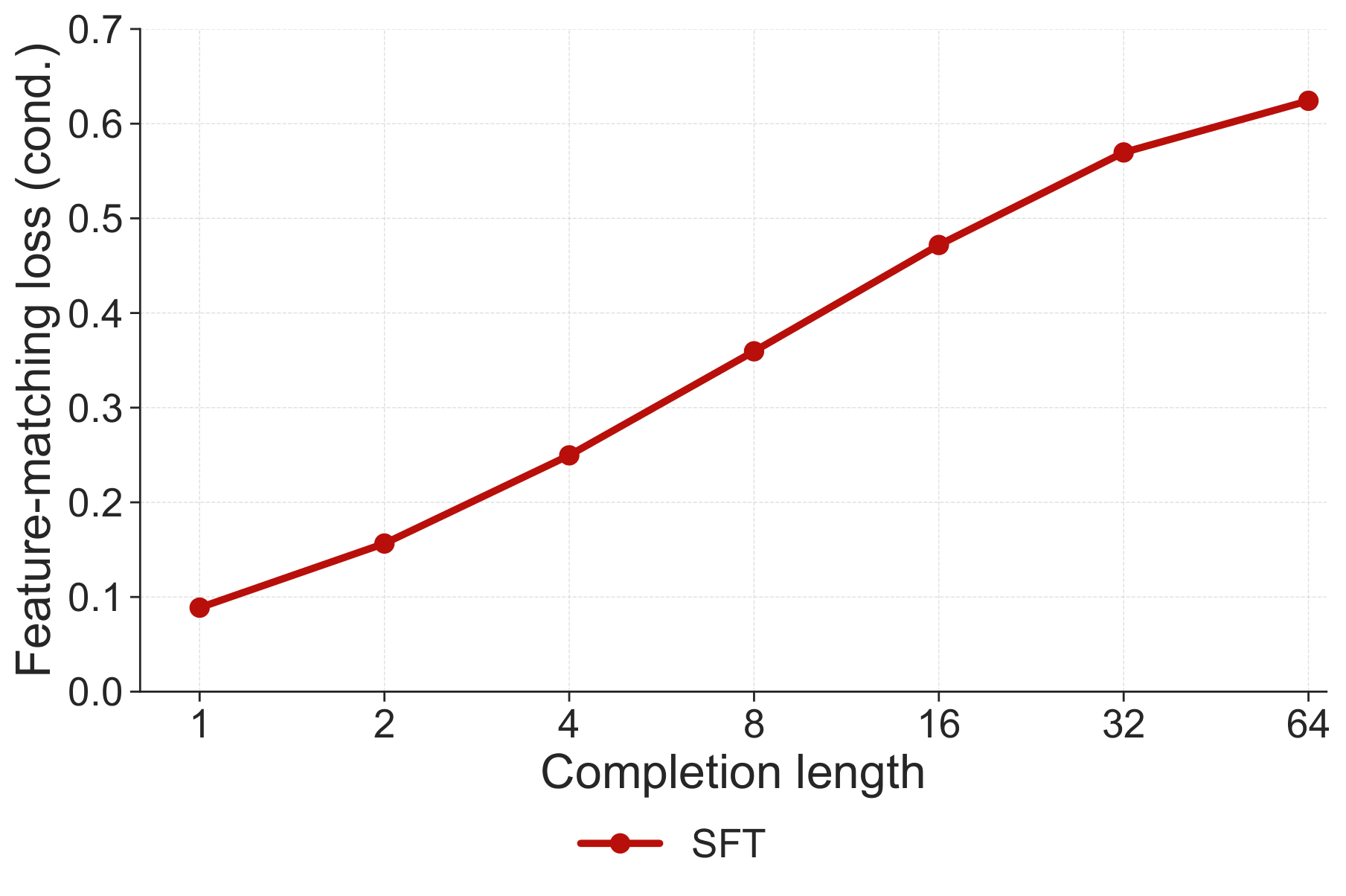
- Compute feature-matching rewards with an alignment term and a diversity term.
- Update the generator with an RLOO / REINFORCE-style policy-gradient step.
- Optionally mix in standard cross-entropy regularization.
Matching Features, Not Tokens:
Energy-Based Fine-Tuning
of Language Models
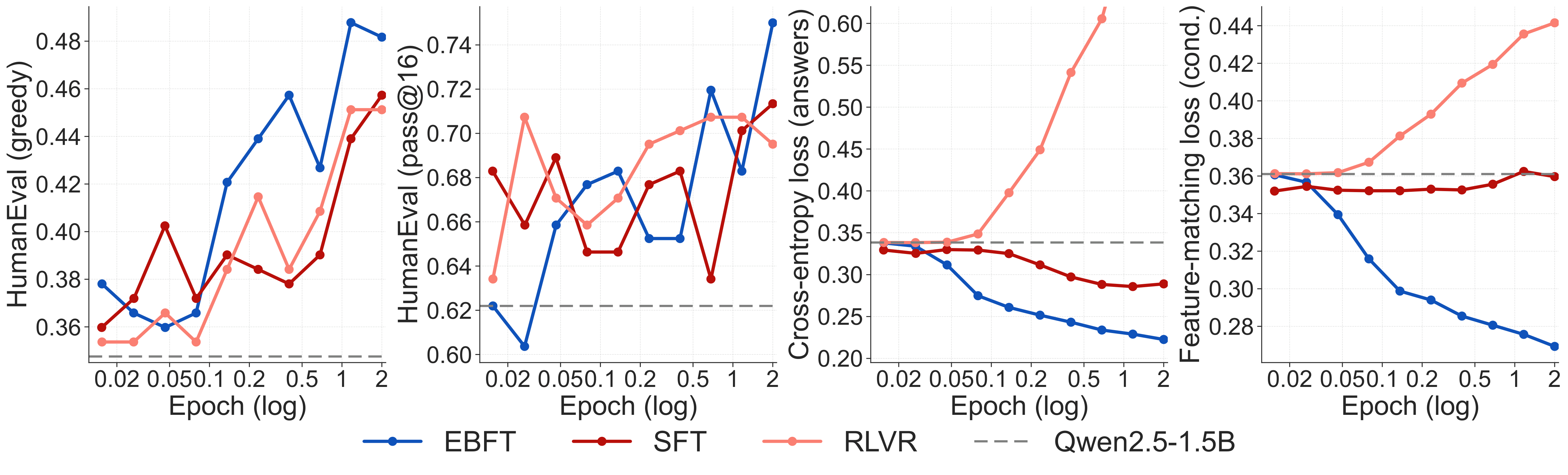
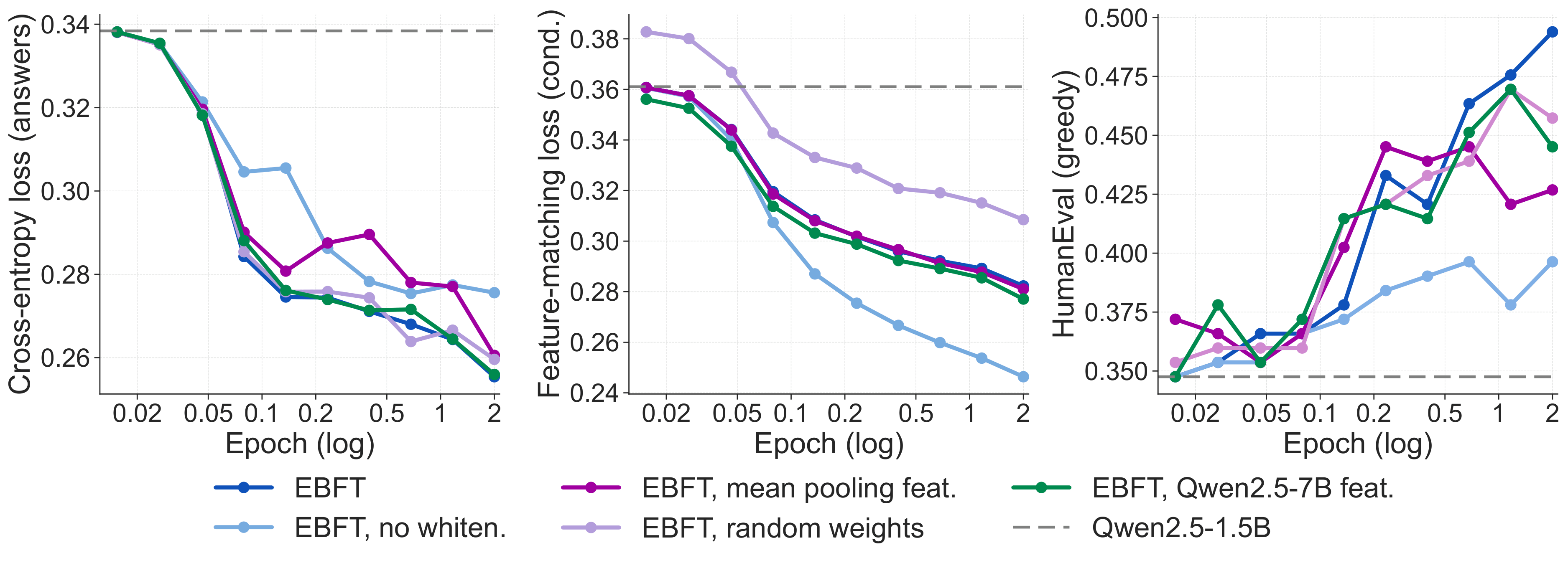
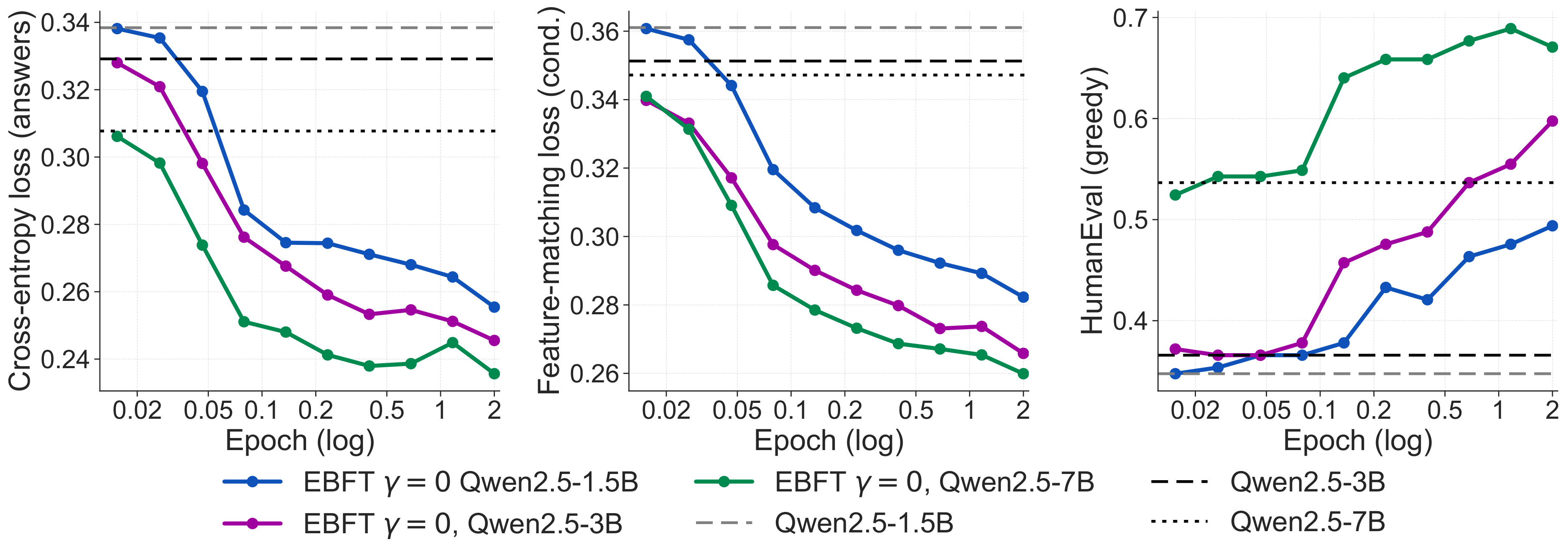
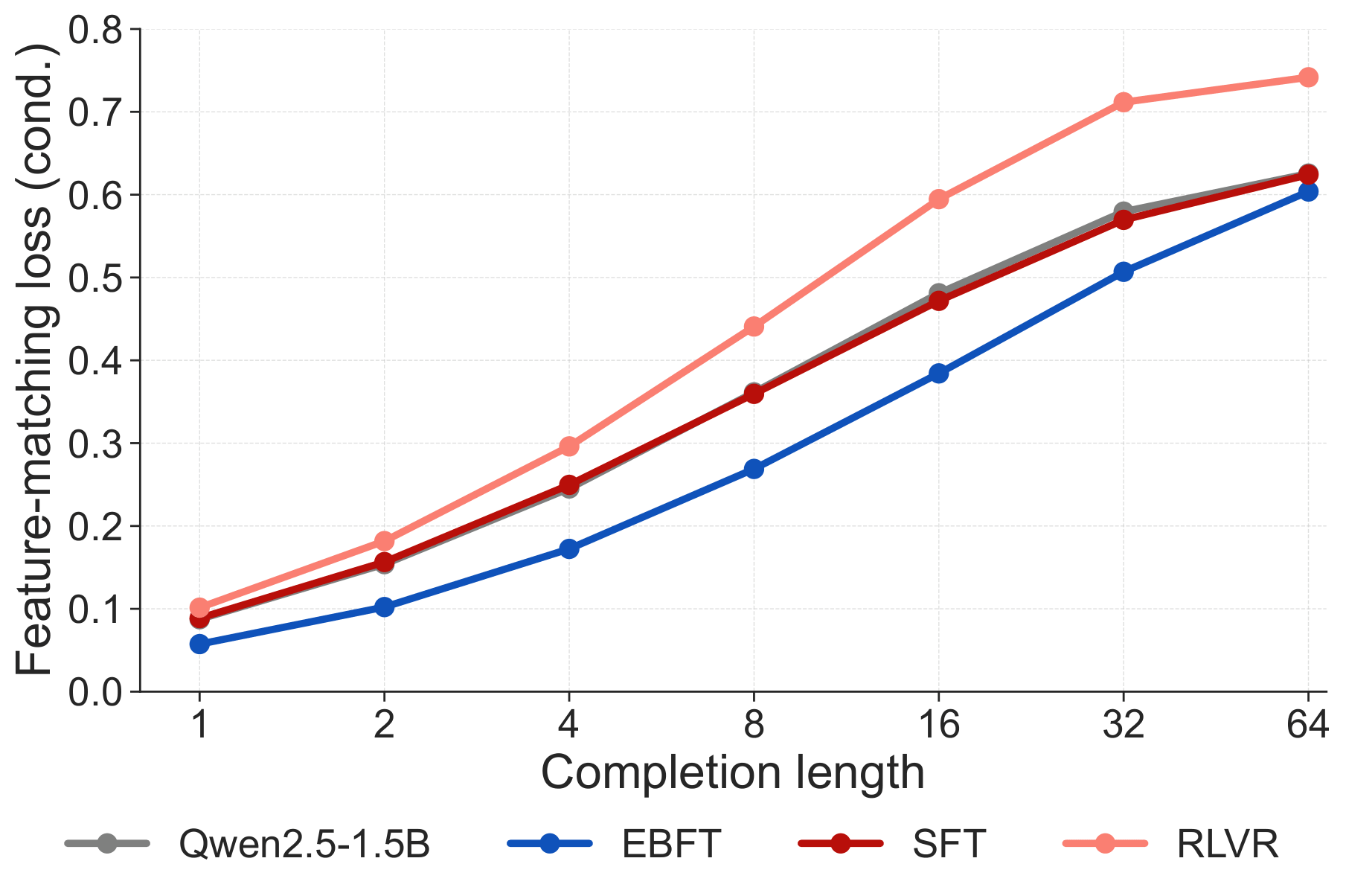
TL;DR. Language models train on ground-truth text but must generate from their own outputs. This mismatch compounds with sequence length: errors drift the model off-distribution, and neither SFT (which never sees its own rollouts) nor RLVR (which provides only a scalar correctness signal) directly addresses the resulting distributional shift. Energy-Based Fine-Tuning (EBFT) introduces a feature-matching objective that measures whether the statistics of model-generated completions match those of ground-truth completions in the activation space of a frozen pre-trained model. EBFT matches or exceeds RLVR on downstream accuracy, achieves better validation cross-entropy compared to SFT despite not directly optimizing it, and requires no task-specific reward or verifier.
Energy-Based Fine-Tuning (EBFT) overview. For each prompt $c$, the generator $p_\theta$ samples $n$ on-policy completions (partial rollouts). A frozen feature network $\phi$, initialized from the generator, embeds the concatenated prompt–completion sequences, producing feature vectors for both sampled and ground-truth completions. EBFT assigns each sample a feature-matching reward that encourages alignment with the ground-truth feature moment while discouraging collapse via a leave-one-out diversity term. The generator is updated with a REINFORCE estimator using an RLOO baseline, yielding a dense sequence-level learning signal under the model's own rollouts.